Introduction
Eukaryotic genomes are full of repeated DNA sequences . These repeated DNA sequences come in all types of sizes and are typically designated by the length of the core repeat unit and the number of contiguous repeat units or the overall length of the repeat region.
1. Long repeat units may contain several hundred to several thousand bases in the core repeat. These regions are often referred to as satellite DNA and may be found surrounding the chromosomal centromere. The term satellite arose due to the fact that frequently one or more minor satellite bands were seen in early experiments involving equilibrium density gradient centrifugation.
2. The core repeat unit for a medium length repeat, sometimes referred to as a minisatellite or a VNTR (variant number of tandem repeats), is in the range of approximately 10–100 bases in length.
3. DNA regions with repeat units that are 2–6 bp in length are called microsatellites, simple sequence repeats (SSRs), or short tandem repeats (STRs).
STRs have become popular DNA repeat markers because they are easily amplified by the Polymerase Chain Reaction(PCR) without the problems of differential amplification. This is due to the fact that both alleles from a heterozygous individual are similar in size since the repeat size is small.
The number of repeats in STR markers can be highly variable among individuals, which make these STRs effective for human identification purposes.
Literally thousands of polymorphic microsatellites have been characterized in human DNA and there may be more than a million microsatellite loci present depending on how they are counted. Regardless, microsatellites account for approximately 3% of the total human genome. STR markers are scattered throughout the genome and occur on average every 10000 nucleotides.
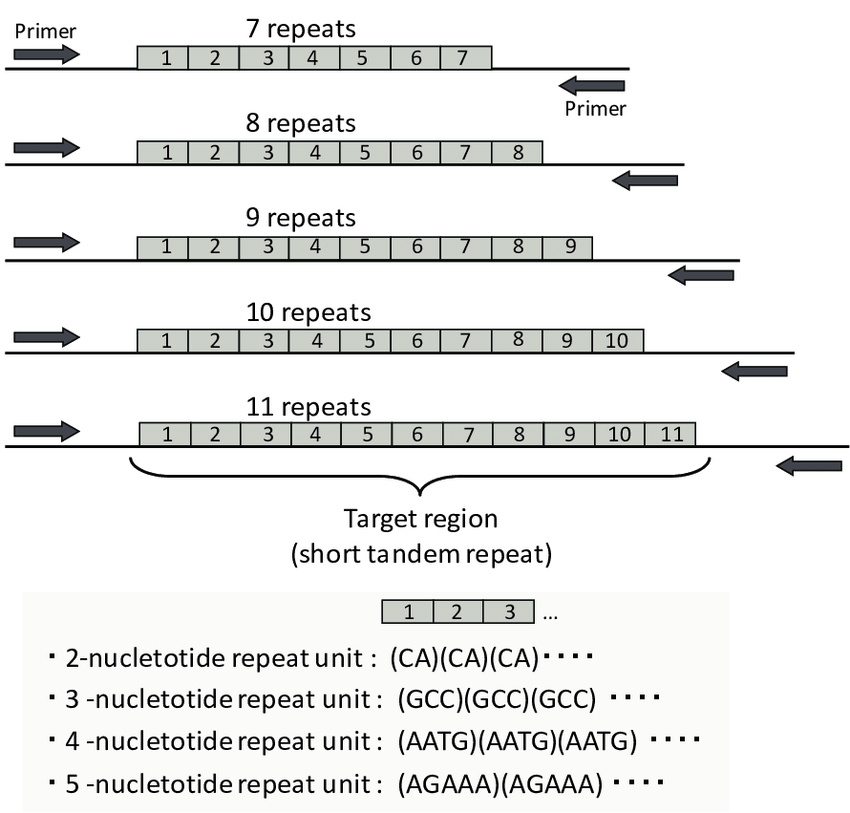
Image Credit
ISOLATION AND TYPES OF STR MARKERS
In order to perform analysis on STR markers, the invariant flanking regions surrounding the repeats must be determined. Once the flanking sequences are known then PCR primers can be designed and the repeat region amplified for analysis.
STR repeat sequences are named by the length of the repeat unit. Dinucleotide repeats have two nucleotides repeated next to each other over and over again. Trinucleotides have three nucleotides in the repeat unit, tetranucleotides have four, pentanucleotides have five, and hexanucleotides have six repeat units in the core repeat. tetranucleotide repeats have become the most popular STR markers for human identification.
Microvariants are alleles that contain incomplete repeat units. Perhaps the most common example of a microvariant is the allele 9.3 at the TH01 locus, which contains nine tetranucleotide repeats and one incomplete repeat of three nucleotides because the seventh repeat is missing a single adenine out of the normal AATG repeat unit.
DESIRABLE CHARACTERISTICS OF STRs USED IN FORENSIC DNA TYPING
For human identification purposes it is important to have DNA markers that exhibit the highest possible variation or a number of less polymorphic markers that can be combined in order to obtain the ability to discriminate between samples.
forensic specimens are often challenging to PCR amplify because the DNA in the samples may be severely degraded (i.e., broken up into small pieces). Mixtures are prevalent as well in some forensic samples, such as those obtained from sexual assault cases containing biological material from both the perpetrator and victim. The small size of STR alleles (~100–400bp) compared to minisatellite VNTR alleles (~400–1000bp) make the STR markers better candidates for use in forensic applications where degraded DNA is common. PCR amplification of degraded DNA samples can be better accomplished with smaller product sizes .
Allelic dropout of larger alleles in minisatellite markers caused by preferential amplification of the smaller allele is also a significant problem with minisatellites. Furthermore, single base resolution of DNA fragments can be obtained more easily with sizes below 500bp using denaturing polyacrylamide gel electrophoresis. Thus, for both biology and technology reasons the smaller STRs are advantageous compared to the larger minisatellite VNTRs. Among the various types of STR systems, tetranucleotide repeats have become more popular than di- or trinucleotides.
A biological phenomenon known as ‘stutter’ results when STR alleles are PCR amplified. Stutter products are amplicons that are typically one or more repeat units less in size than the true allele and arise during PCR because of strand slippage. Depending on the STR locus, stutter products can be as large as 15% or more of the allele product quantity with tetranucleotide repeats. With di- and trinucleotides, the stutter percentage can be much higher (30% or more) making it difficult to interpret sample mixtures. In addition, the four base spread in alleles with tetranucleotides makes closely spaced heterozygotes easier to resolve with size-based electrophoretic separations compared to alleles that could be two or three bases different in size with dinucleotides and trinucleotide markers, respectively. Thus, to summarize, the advantages of using tetranucleotide STR loci in forensic DNA typing over VNTR minisatellites or di- and trinucleotide repeat STRs include:
■ A narrow allele size range that permits multiplexing;
■ A narrow allele size range that reduces allelic dropout from preferential amplification of smaller alleles;
■ The capability of generating small PCR product sizes that benefit recovery of information from degraded DNA specimens; and
■ Reduced stutter product formation compared to dinucleotide repeats that benefit the interpretation of sample mixtures.
The selection criteria for candidate STR loci in human identification applications include the following characteristics :
■ High discriminating power, usually >0.9, with observed heterozygosity >70%;
■ Separate chromosomal locations to ensure that closely linked loci are not chosen;
■ Robustness and reproducibility of results when multiplexed with other markers;
■ Low stutter characteristics;
■ Low mutation rate; and
■ Predicted length of alleles that fall in the range of 90–500bp with smaller sizes better suited for analysis of degraded DNA samples.
ALLELIC LADDERS
An allelic ladder is an artificial mixture of the common alleles present in the human population for a particular STR marker .They are generated with the same primers as tested samples and thus provide a reference DNA size for each allele included in the ladder. Allelic ladders have been shown to be important for accurate genotype determinations .These allelic ladders serve as a standard like a measuring stick for each STR locus. They are necessary to adjust for different sizing measurements obtained from different instruments and conditions used by various laboratories . Allelic ladders are constructed by combining genomic DNA or locus-specific PCR products from multiple individuals in a population, which possess alleles that are representative of the variation for the particular STR marker . The samples are then co-amplified to produce an artificial sample containing the common alleles for the STR marker .Allele quantities are balanced by adjusting the input amount of each component so that the alleles are fairly equally represented in the ladder.
THE 13 CODIS STR LOCI
national DNA database known as CODIS (Combined DNA Index System). 13 core STR loci were chosen to be the basis of the future CODIS national DNA database. The 13 CODIS core loci are CSF1PO, FGA, TH01, TPOX, VWA, D3S1358, D5S818, D7S820, D8S1179, D13S317, D16S539, D18S51, and D21S11. When all 13 CODIS core loci are tested, the average random match probability is rarer than one in a trillion among unrelated individuals . The three most polymorphic markers are FGA, D18S51, and D21S11, while TPOX shows the least variation between individuals.
the 13 CODIS core STR loci may be divided up into four categories:
1. Simple repeats consisting of one repeating sequence: TPOX, CSF1PO, D5S818, D13S317, D16S539; 2. Simple repeats with non-consensus alleles (e.g., 9.3): TH01, D18S51, D7S820;
3. Compound repeats with non-consensus alleles: VWA, FGA, D3S1358, D8S1179;
4. Complex repeats: D21S11.
GENDER IDENTIFICATION WITH AMELOGENIN
The ability to designate whether a sample originated from a male or a female source is useful in sexual assault cases, where distinguishing between the victim and the perpetrator’s evidence is important. Likewise, missing persons and mass disaster investigations can benefit from gender identification of the remains. Over the years a number of gender identification assays have been demonstrated using PCR methods .By far the most popular method for sex-typing today is the amelogenin system as it can be performed in conjunction with STR analysis. Amelogenin is a gene that codes for proteins found in tooth enamel. These primers flank a 6bp deletion within intron 1 of the amelogenin gene on the X homologue .PCR amplification of this area with their primers results in 106bp and 112bp amplicons from the X andY chromosomes, respectively. Primers, which yield a 212bp X-specific amplicon and a 218bp Y-specific product by bracketing the same 6bp deletion, were also described in the original amelogenin paper and have been used in conjunction with the D1S80 VNTR system.
An advantage with the above approach, i.e., using a single primer set to amplify both chromosomes, is that the X chromosome product itself plays a role as a positive control. This PCR-based assay is extremely sensitive. Other regions of the amelogenin gene have size differences between the X and Y homologues and may be exploited for sex-typing purposes. Thus, by spanning various deletions of the X and/or Y chromosome, it is possible togenerate PCR products from the X and Y homologues that differ in size and contain size ranges that can be integrated into future multiplex STR amplifications.
Can I get these materials on my email or in PDF?I found them very informative.
You can use save as PDF in your Chrome browser!